

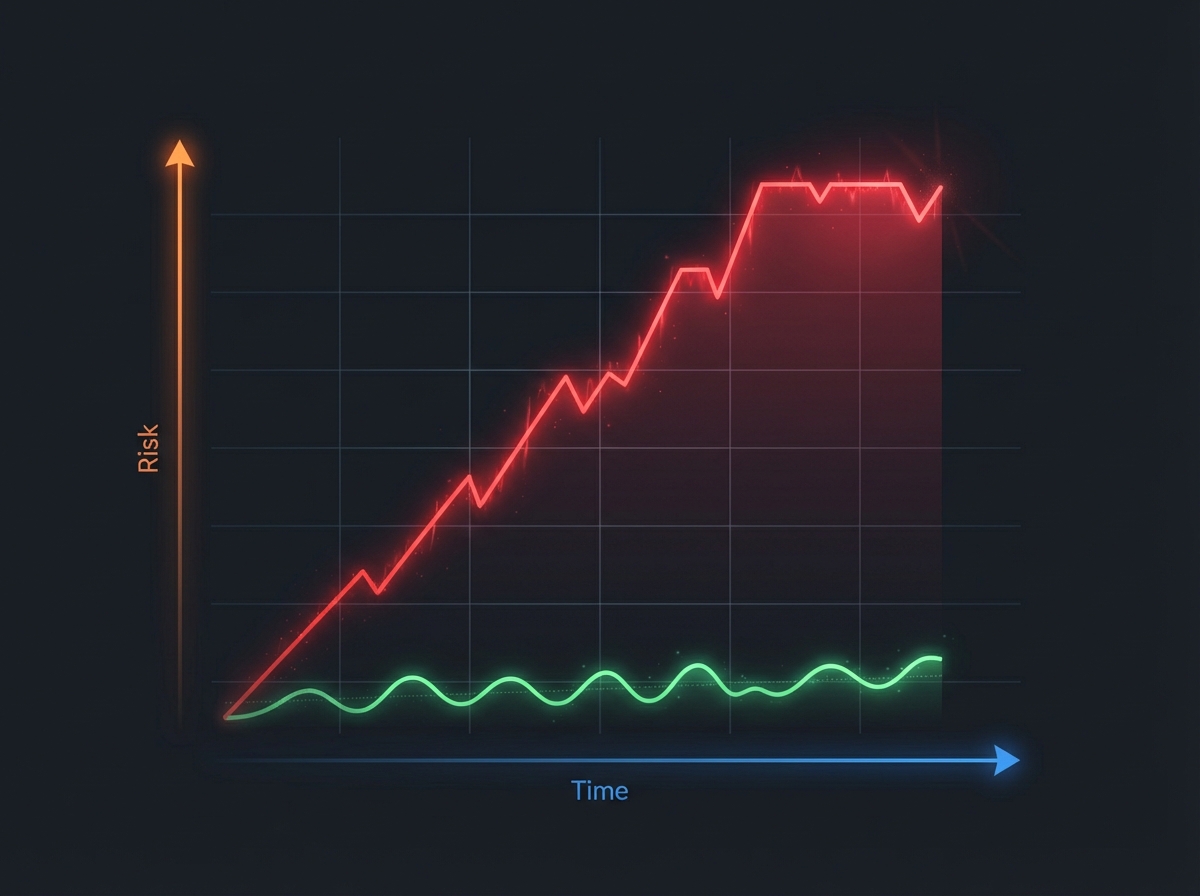
The Big Bang Approach: High Risk, High Reward?
The Big Bang migration strategy is conceptually simple: you build the new system in isolation while the legacy platform continues to serve customers. Once feature parity is achieved, you execute a cutover—shutting down the old system and launching the new one simultaneously. It is the software equivalent of a heart transplant, requiring the organization to switch vital functions in a single, high-stakes event.
There is a distinct psychological appeal to this method. For engineering teams, it promises a “greenfield” environment free from the shackles of technical debt. Developers can architect the ideal solution without hacking around decades of spaghetti code, obsolete dependencies, or restrictive data structures. Stakeholders are often drawn to the illusion of a clean break, believing that a singular, focused effort will deliver a pristine product faster than piecemeal updates.
However, this isolation creates a dangerous phenomenon known as the “tunnel effect.” For months or even years, the business sees zero tangible value while development takes place in a vacuum. During this blackout period, business requirements and user expectations inevitably evolve. Teams often emerge from the tunnel with a system that matches the original specifications perfectly but fails to meet the current reality of the market.
Beyond the strategic misalignment, the Big Bang approach introduces catastrophic operational failure modes:
- Data Migration Complexity: Moving terabytes of historical data in a single weekend window allows no room for error. If data mapping logic is slightly off, corruption spreads instantly across the entire new database, affecting every user simultaneously.
- The Rollback Impossibility: Once the switch is flipped and new transactions are processed by the modern system, reverting to the old platform becomes a nightmare. You cannot easily sync new data back to the old schema, meaning there is effectively no safety net.
Because of these all-or-nothing dynamics, Big Bang migrations are statistically the most likely to fail. When the cutover date arrives and critical bugs are discovered, the only option is to delay the entire launch. This leads to the infamous cycle of “just six more months,” rapidly inflating costs and frequently ending in total project abandonment.
The Incremental Path: Mastering the Strangler Fig Pattern
Unlike the high-stakes gamble of a Big Bang rewrite, incremental migration focuses on replacing a legacy system piece by piece. The gold standard for this approach is the Strangler Fig pattern, a concept popularized by Martin Fowler. Inspired by the natural phenomenon where a fig vine grows around a host tree until it eventually replaces it, this software architecture pattern allows you to modernize a system without taking the existing application offline.
The mechanism relies heavily on an interception layer, typically an API gateway or a reverse proxy, placed directly in front of your legacy application. Initially, this proxy routes all traffic to the old system. As you build modern microservices or modules to replace specific functionalities—such as user authentication or inventory management—the proxy is updated to route requests for those distinct features to the new architecture. Over time, the new system grows while the legacy system shrinks.
This approach necessitates a period of coexistence. The monolith and the new microservices run in parallel, often sharing data through synchronization processes or dual-write strategies. To the end-user, the experience remains seamless; they are unaware that the underlying machinery is changing beneath their feet. This strategic parallelism ensures that business operations continue uninterrupted while the modernization effort proceeds in the background.
Adopting the Strangler Fig pattern transforms modernization from a cliff-edge deployment into a manageable journey, offering several distinct advantages:
- Immediate Value Delivery: You can release modernized features to production as soon as they are ready, rather than waiting years for a full system completion.
- Faster Feedback Loops: Because new code hits production early, you gather real user data and catch bugs immediately, preventing the accumulation of hidden technical debt.
- Ability to Pause or Pivot: The granular nature of the migration allows business leaders to pause development or shift priorities based on changing market conditions without losing the progress already made.

Decision Matrix: When to Choose Which Path
Let’s be clear: the "Big Bang" approach isn't universally bad. If you are migrating a small, standalone application with a limited user base, or moving off a legacy platform that is fundamentally incompatible with modern protocols where bridging is technically impossible, a rapid cut-over strategy might be the most efficient route. However, for mission-critical core systems, the choice requires a rigorous evaluation of your environment.
To determine the right strategy for your modernization efforts, assess your architecture against these four critical pillars:
- System Coupling: Can specific business domains be isolated? If your modules are loosely coupled, an incremental approach is natural. If you are dealing with a highly entangled monolith, you might feel forced toward a Big Bang; however, the effort to decouple via the Strangler Fig pattern often pays dividends in long-term maintainability.
- Business Urgency: When does the business need to see value? Big Bang migrations delay all ROI until the final launch date, which could be years away. If you need to release specific features or compliance updates immediately, incremental migration allows you to prioritize and ship high-value components first.
- Risk Tolerance: What is the acceptable cost of downtime? If your organization cannot tolerate extended service interruptions or massive rollbacks, Big Bang is likely too dangerous. Incremental shifts allow you to fail small and recover quickly without taking the entire enterprise offline.
- Data Complexity: High data volume and complex schema dependencies make massive data migrations incredibly risky. Incremental strategies allow for parallel runs and gradual data verification, significantly reducing the chance of corruption.
Ultimately, the decision often comes down to a trade-off between logistical complexity and existential risk. While running legacy and modern systems in parallel introduces a "cost of coordination," this expense is almost always lower than the catastrophic "cost of failure" inherent in a botched Big Bang deployment. For core systems, paying the price for coordination ensures that you survive the journey.

Tactical Execution: Managing Data and Dual-Writes
While rewriting business logic is a significant engineering effort, the true villain in incremental migration is almost always data synchronization. When you run legacy and modern systems in parallel, ensuring they both reflect the "truth" without corrupting data is paramount. This challenge requires moving beyond simple database backups and adopting real-time synchronization strategies to bridge the gap between the old and new worlds.
The most direct approach is the Dual-Write strategy. In this model, the application modifies its code to write data to both the legacy database and the new data store simultaneously. While this ensures high data consistency, it introduces significant complexity. Developers must handle edge cases where a write succeeds in the old system but fails in the new one, potentially leading to immediate data drift. Furthermore, dual-writes effectively double the database latency for every user transaction.
An alternative, often more resilient method is Change Data Capture (CDC). Instead of burdening the application layer with double duty, CDC tools listen to the transaction logs of the legacy database and replicate changes to the new system asynchronously. This decouples the migration process from the user experience and reduces the risk of performance degradation, though it requires engineers to design for eventual consistency.
Regardless of the synchronization method selected, you must validate the new system dynamically before a full cutover. To route traffic safely, rely on two critical mechanisms:
- Feature Flags: specific toggles that allow you to route live traffic between the old and new implementations granularly. This enables canary releases where you migrate 1% of users first, allowing for an instant rollback via the toggle if issues arise.
- Shadow Mode and Parity Testing: Route traffic to both systems but only return the legacy response to the user. In the background, automated tests compare the outputs of the new system against the trusted legacy system to ensure 100% logic parity before the new system ever faces a real user.


